
柒小希破次元硬件首秀,AI生圖解鎖創意新邊界
全新虛擬代言人柒小希作為七彩虹擁抱 Z 世代次元文化的先鋒。這位賽博城精英領航者攜首發硬件套裝降臨“玩創星球”,包括iGame GeForce RTX 5070 Advanced OC Senna顯卡、iGame C25A Senna機箱及iGame X870 Senna V14主板,紅銀戰甲涂裝與RGB光效交織,將萌動活力與硬核性能完美融合。玩家置身于柒小希主題桌搭專區——環繞硬核裝備的角色立繪及元氣周邊宇宙,不僅能沉浸式感受深度IP定制賦予的硬件情感聯結,更能親證“熱愛如何被鍛造為可觸的玩創次元”。

尤其是這套家族產品搭載了七彩虹最新“自在星球”硬件控制軟件,其中具有一個可愛的“柒小希AI桌寵”,隨著軟件版本的迭代,她已經不只是實現于玩家的基礎對話交流,具工作人員介紹,后續的發展中她會學會更多技能,包括音樂律動舞蹈、語音硬件控制、游戲休閑交互等等,她的存在會更加給七彩虹原本優異的軟件控制系統帶來更具有文化屬性的生態發展,形成七彩虹玩家桌面交互的新生態。

說到交互就不得不提右側的 AI 生圖互動區,其基于 Flux 模型與定制 LORA 技術,玩家現場拍照 30秒即生成專屬 3D 樹脂質感數字玩偶,圓潤萌動造型暗藏硬件彩蛋,掃碼直取實體收藏卡,將次元創意化為可觸信物。這不僅是七彩虹對 AIGC 應用的深度探索,更為內容創作者開辟了打破傳統邊界的個性化工具,彰顯品牌擁抱 Z 世代次元文化的先鋒姿態。

iGame影II內存發布:超頻性能與國風美學雙突破
七彩虹此次發布了最新的“iGame影II DDR5”內存,旗艦型號以6400MHz高頻、C28時序及1.4V超低電壓打造性能標桿。專為AMD Ryzen 9000平臺優化,一鍵超頻即可釋放電競性能潛力,電壓降低帶來更大超頻空間。設計上以水墨風格重塑硬核美學,散熱馬甲蝕刻凌厲"影"字,搭配動態RGB燈效與雙面透光銘板。同步推出96GB(48GB×2)大容量套裝,解決創作軟件卡頓問題,6000C28 24G*2等多規格覆蓋游戲與生產力場景。

筆記本矩陣火力全開,隱姬IP賦能電競潮流
七彩虹隱星P16 Pro系列與iGame Origo旗艦本領銜筆記本專區,以高性能與獨特設計征服年輕玩家。隱星P16 Pro融入“戰艦”元素,霧嶼白啞光機身搭載NVIDIA GeForce RTX50系列GPU及Intel Core HX處理器,輕薄便攜中兼顧3A游戲暢玩,伴生二次元IP“隱姬”提供獨特情感陪伴。iGame M15/M16 Origo系列則以宇宙黑洞為靈感,配備2.5K 300Hz ACR幻彩屏及200W性能釋放,七彩虹星知島AI助手加持下,成為游戲與創作的全能“六邊形戰士”。同時,25款COLORFIRE MEOW R16游戲本升級機甲風設計,冰川白配色搭載AMD銳龍7H 255處理器與RTX 5070 GPU,兼顧高顏值與AI處理性能。這些產品不僅滿足電競娛樂需求,更以合理價格策略推動高性能筆記本普及,印證七彩虹在移動硬件領域的生態布局,為行業樹立了性能與潮流融合的新標桿。

RTX超級玩家體驗區,高幀游戲定義競技未來
iGame GeForce RTX超級玩家體驗區成為幀率控和電競黨的天堂,展示Blackwell架構顯卡的革命性突破。現場四臺主機搭載RTX 5080/5070 Ti顯卡,運行《燕云十六聲》和《永劫無間》,DLSS4技術加持下幀率飆升到傳統渲染的近4倍!武俠世界從未如此絲滑流暢,畫面細節更是智能優化到極致。電競區則聚焦低延遲競技:四臺配備RTX 5060家族顯卡的主機運行《反恐精英:全球攻勢》與《無畏契約》,NVIDIA Reflex技術搭配AOC 2K 280Hz高刷顯示器,助玩家搶占先機。

除七彩虹本展臺外,在英偉達展臺技術體驗區提前感受DLSS4技術革新:本月即將發布的《明末:淵虛之羽》與即將支持的科幻開放世界《鳴潮》,玩家可通過搭載iGame RTX 5080 Vulcan顯卡與CVN X870 ARK主板的主機,雙Demo驗證Blackwell架構“性能x能效”雙突破,為玩家鋪就次世代游戲的技術坦途。

不僅如此,七彩虹還與完美世界深度合作,《反恐精英:全球攻勢》全場設備采用搭載七彩虹戰斧RTX 5070與戰斧Z890主板的游戲電競主機,作為中國網吧上座率穩居TOP1的國民級競技游戲,CS2的高幀率、低延遲需求與戰斧系列的穩固特性深度契合。七彩虹以“性能冗余+易維護”設計直擊網吧痛點,為行業提供兼具穩定性與視覺張力的硬件解決方案,進一步強化電競生態布局。

AI PC重塑生產力,應用工作流顛覆設計流程
RTX AI PC體驗區展示七彩虹在AI算力應用的前瞻性。iGame Ultra Family主機運行《永劫無間》PC版,NVIDIA ACE技術支持本地推理AI隊友,實時語音交互媲美真人組隊,為游戲社交帶來革新。更驚艷的是COLORFIRE MEOW復古電玩主機的創意體驗:搭載即致AI應用,設計師通過手繪草圖或3D模型秒級生成高質量渲染圖,集成國內建筑設計大模型,優化景觀與室內設計細節。七彩虹以GeForce RTX 50系列GPU驅動AI工作流,讓創作者擺脫機械操作,聚焦核心創意。這響應了行業對高效生產力的需求,凸顯AI硬件如何賦能建筑、藝術領域,推動AIGC從概念走向實用化。

強勁硬件、激情電競的沉浸式矩陣
在玩創星球的核心展區,七彩虹打造了開放式硬件墻,左側懸掛iGame GeForce RTX 5080 Vulcan OC與RTX 5070 Ti Vulcan W OC顯卡,真空電鍍裝甲與LCD智屏構成光效交響;演繹多元美學——Advanced系列的賽博朋克金屬背板、Ultra系列的波普藝術涂裝、COLORFIRE MEOW「RTX 5060橘影橙」萌系治愈風,剛柔碰撞間詮釋性能即藝術。中部矗立主板圖騰:iGame Z890 VULCAN黑/白火神以16+2相105A供電模組釋放旗艦算力,碳纖維散熱裝甲如機甲戰袍;其下方CVN X870 ARK方舟主板 以舷號蝕刻軍工鋁罩,專利快拆卡扣實現徒手更換顯卡的革命性體驗。在右側觀眾可看到包括iGame影II內存在內的各類存儲硬件,在展架的零距離交互中,感受七彩虹重構硬件美學的硬核哲學。

七彩虹一直致力于給多重玩家場景提供硬件裝備支持,更是一直緊密同中國電競文化及戰隊合作。此次展會人氣巔峰的亮點,當屬七彩虹邀請了其今年合作的全球知名《英雄聯盟》電競戰隊“TES滔博戰隊”來到舞臺現場,明星選手近距離與玩家互動,點燃現場氛圍!

在2025 BILIBILI WORLD展會中,七彩虹通過次元IP聯動、高性能產品矩陣與沉浸式AI互動,詮釋“玩轉AI,創意出彩”理念。同時擁有雷蛇專業電競外設與AOC高刷顯示器的加持,更構建了從核心硬件到終端輸出的完整體驗鏈。這不僅是AIPC時代加速到來的印證,更彰顯七彩虹以創新硬件賦能電競、創作與生活的生態布局——在引領高算力、低延遲、個性化科技浪潮的同時,攜手合作伙伴輻射二次元文化圈層,重塑Z世代科技體驗!
]]>

在本次“RTX AI創作加速體驗區”的正式啟用典禮中,涵蓋了RTX AI創作加速技術展示、七彩虹RTX AI PC新品推介,火星時代教育師生現場創作等多個關鍵環節,并隆重舉行了RTX AI加速體驗區的揭牌儀式。此次活動不僅彰顯了技術的創新力量,更凸顯了教育與AI產業發展之間的密切合作關系。在此次盛大的活動現場,眾多業內頂尖的教育家、設計師和媒體界的專業精英們蒞臨現場,共同探索和體驗AI技術所帶來的無限可能。在這里,與會嘉賓及媒體親眼見證由火星時代教育、NVIDIA及七彩虹三方協力打造的創意加速區,它匯聚了最先進的AI技術與強大的AIPC硬件,結合火星時代的專業教育資源,為AI創作領域注入前所未有的活力。此次三方合作體現了科技與教育融合的先進實踐,樹立了AI與CG技術整合的高標準,預示了未來“科技+教育”的發展趨勢。

據介紹,NVIDIA和七彩虹與火星時代教育很早就開始探索借助科技為學習與創作效率提速,火星時代2022年開始探索AI軟件在設計工作流中的輔助作用,并率先在其影視部分專業引入NVIDIA Studio AI應用做試點教學。2022年末,火星時代正式成為NVIDIA Studio中國區生態合作伙伴,依托七彩虹設計師主機共同打造的創意是空間創意設計在火星時代北京校區落成,三方還在2023年末推出《AI設計商業化必修公開課》,結合實操案例算力測評,為大眾普及AIGC創作知識,助力創意加速。

今年初,七彩虹針對AIGC領域,提出了“玩轉AI,創意出彩”的理念,并推出了一系列融合獨特美學設計與技術創新思路的iGame RTX AI PC產品。其中包括了iGame Ultra家族硬件以及將星系列筆記本電腦。而在活動現場提供技術體驗的型號為「將星X17 Pro MAX」和「將星X16 Pro」,它們分別配備了頂級的GeForce RTX 4090和GeForce RTX 4070筆記本電腦GPU,這兩款筆記本電腦以其強大的計算性能,在現場活動中輕松應對了SD圖像轉繪、SD+Photoshop、SD+Blender、NVIDIA Canvas等多個創意應用程序的運行。這些高性能筆記本電腦,不僅為現場觀眾帶來了前所未有的創作體驗,也展示了其在圖形處理、視頻編輯等創意工作領域的卓越能力。

而在現場的AI PC設備“iGame Ultra家族硬件”AIPC當中,還部署了Stable Diffusion ComfyUI/WebUI,NVIDIA技術人員及火星時代教育的老師們現場演示了ComfyUI的視頻驅動圖像動畫的效果,通過現場錄制的視頻,驅動AI生成的角色靜幀,能夠實時在部署的工作流中完成人物動作和生成角色的動作同步交互,體現AI創作的極大趣味性。通過ComfyUI的 工作流,可以通過用戶現場拍攝的照片,按照被攝者本人的面部特征,生成不同造型的超人圖片,快速完成特定類型的海報效果。現場也通過WebUI配合Photoshop和Blender,進行多軟件結合,完成游戲場景概念設計,商業海報等效果,現場創作完成商業作品落地。

七彩虹旗下國創新生代高端硬件iGame的家族系列產品“iGame ULTRA”家族硬件,產品從內到外采用了統一的“pop(波普)”設計元素,彰顯新生代創作者們特立獨行的風格,高顏值之外性能也非常強勁,強大的AIPC裝備的搭載iGame GeForce RTX 4080 SUPER Ultra W OC 16GB,擁有10240個CUDA核心及16GB GDDR6X極速顯存,高達836的AI TOPS的本地GPU算力將高效地完成各項AIGC任務,因此使用SD進行創作將會加速工作流。現場參會人員也用它們親身體驗了Stable Diffusion 。ComfyUI+InstantID超人照片生成,SD Web UI+AI動畫以及SD+Blender Optix渲染等,強大的iGame Ultra家族硬件為AI創作實現全力加速,幫助學習者快速地完成商業作品,助力靈感完美落地。-

在活動現場的七彩虹筆記本類產品,除了有將星系列之外,也有一款相當亮眼的新品,那就是「七彩虹 源 N14全能筆記本電腦」。這款筆記本電腦同樣搭載了高性能的GeForce RTX 4070筆記本電腦GPU,以其全面而強大的功能,滿足了各類創作者對于移動生產力工具的需求。在“源N14”中展示了基于Canvas的AI繪圖技術。在RTX GPU的強大支持下,源N14竟將簡單的筆觸瞬間轉化為栩栩如生的風景圖。對于那些需要在移動中保持高效創作的用戶來說,這些集成了先進AI技術的AIPC筆記本電腦,無疑是提升工作效率、激發創作靈感的理想選擇。

一直以來,七彩虹與眾多知名設計師、藝術家團隊、游戲開發者、電競從業者均建立了緊密聯系,共同探索并致力于為游戲玩家、藝術家、創作者和游戲開發者提供創意應用程序使用期間所需的最佳性能和可靠性;高端硬件子品牌iGame顯卡及家族系列產品所具備的圖形處理技術和多項散熱黑科技更是幫助創意工作者獲得了更好的硬件性能和創意呈現。

通過親身體驗七彩虹AIPC硬件和這些尖端創作工具,參與者們直觀感受到了AI技術在工作流程中的顯著加速效果。這不僅為商業創作注入了新的活力,更展現了AI技術在未來的廣闊應用前景。此次活動是科技與創意的完美結合,充分展示了AI技術在推動行業發展方面的巨大潛力和價值。也讓我們更加期待AI落地應用的前景和明天更加美好。
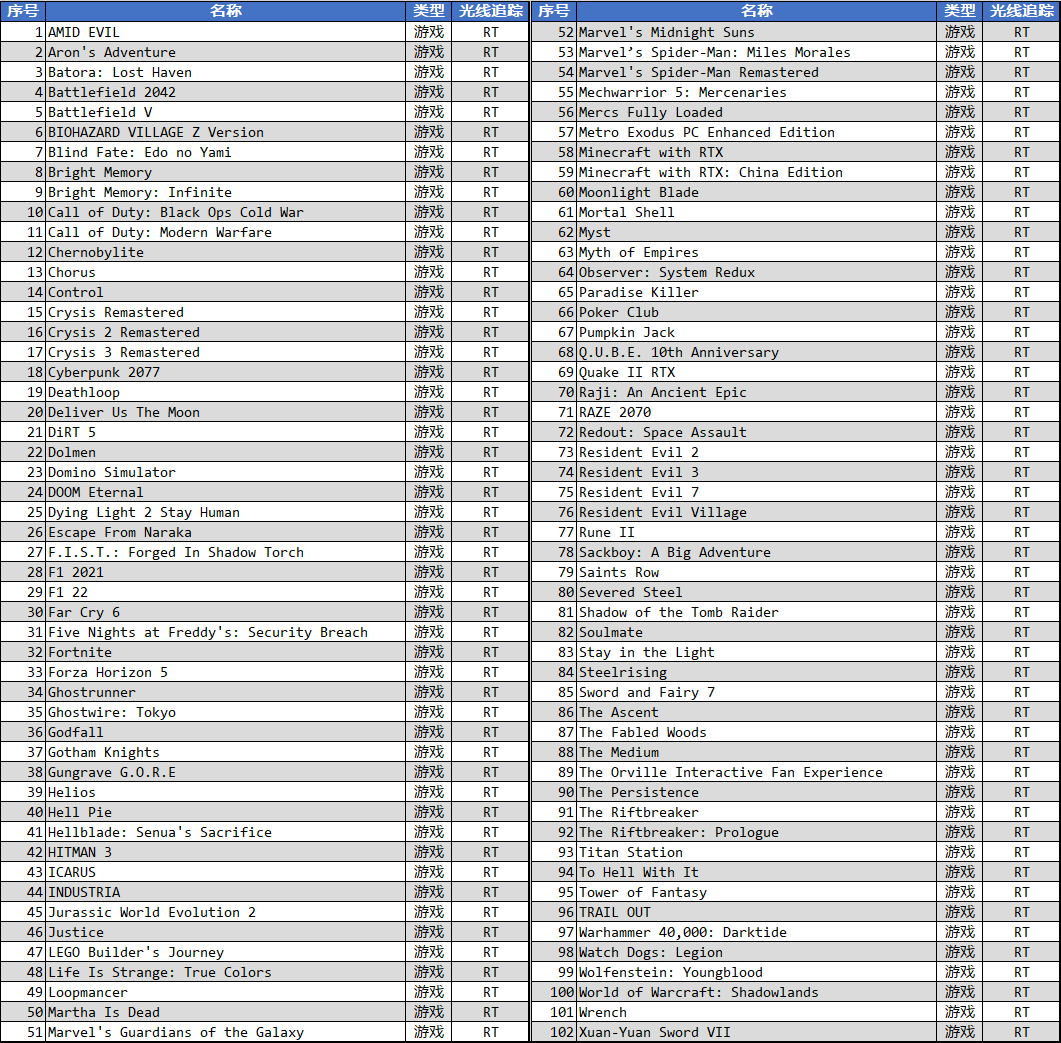
]]>距離 2018 年第一代硬件光線追蹤 GPU GeForce RTX 2080 Ti 發布已經過去了 4 年,根據目前的最新統計,PC 平臺上的光線追蹤游戲已經達到 102 個,粗略平均的話那就是每年 25 個。
其中的一些大作包括例如· 賽博朋克 2077、古墓麗影之暗影、Far Cry 6、漫威蜘蛛俠重制版、地平線 5、生化危機村莊、地鐵離去等等,其中像地鐵離去還出了一個強制要求顯卡支持 DXR 特性的增強版。
除了電子游戲娛樂外,還有不少渲染器也都引入了硬件光線追蹤加速,例如以往只提供 Intel CPU 優化的工業渲染器 Keyshot 等也都第一時間跟進了,原因很簡單,采用硬件光線的確顯著提升了渲染性能,節約了時間提高了生產力。
對顯卡廠商、游戲玩家以及游戲開發商來說,硬件光線追蹤或者說視覺感染力和游戲是相輔相成的關系。
電子游戲是離不開視覺感染力的,硬件光線追蹤為更強的渲染效果提供了可能,這不僅是畫面渲染,還包括了基于光線追蹤的音效處理等對玩家同樣有直觀體驗的特性。
相對于 4 年前的 GeForce RTX 2080 Ti,現在的最新世代 GPU 例如 GeForce RTX 4090、GeForce RTX 4080 在性能方面有了顯著的提升,例如 RTX 2080 Ti 的單精度性能是 14.2 TFLOPS,而新近發布的 RTX 4080 單精度性能根據我之前的實測達到了 51 TFLOPS,提升了接近 2.6 倍,在相當部分游戲中,像 5800X 這樣去年還屬于旗艦的 CPU 已經成為瓶頸。
針對 CPU 瓶頸問題,NVIDIA 為 GeForce RTX 4000 系列引入了名為 DLSS 3 的新超采樣技術,在原來 DLSS 2 空間超分辨率的基礎上,引入了基于硬件光流加速的時間超分辨率或者說幀合成(Frame Generation)技術,能在前后兩幀之間生成一張畫面,在不增加 CPU 開銷的情況下實現更平滑的畫面過渡效果。在實際測試中,DLSS3 FG 能提升大約 30% 以上的幀率。
由于 FG 插幀需要渲染兩幀后才能完成插幀動作,會增加額外的時延,因此 DLSS 3 還結合了 Reflex 低時延技術,用來確保時延不會大幅度增加。
一路下來,你會發現 NVIDIA 在光線追蹤部署方面可謂是有板有眼:中路主打光線追蹤,然后加上不斷升級 DLSS 技術打輔助,面對 AMD 和 Intel 的疊加圍攻下依然不落下風,最近的市場份額甚至是不減反增。
除了硬件不斷增強,NVIDIA 在軟件方面的動作更為有趣。
以 RTX Remix 為例,這是 NVIDIA 趁著 RTX 4090 發布而推出的一個游戲魔改(Mod)工具集。魔改是游戲社區非常盛行的一種文化,已知的魔改作者數量據聞有數百萬,每年下載的游戲魔改模組達到了數十億次,時下流行的 10 款電競游戲里就有 9 款有魔改。
被魔改次數最多的游戲 The Elder Scrolls V: Skyrim(上古卷軸 5:天際)和The Elder Scrolls V: Skyrim Special Edition(上古卷軸 5:天際特別版),其中被下載最多的魔改模組均為圖形方面的魔改包。
要修改游戲的圖形是一件非常困難的事情,需要開發出特定的工具,為每個素材重建新藝術作品,NVIDIA 表示,為了開發 Quake II RTX,動用了 NVIDIA 工程師、美工、QA 團隊數個月時間才搞定,這還是在獲得源代碼以及其他開發人員提供的魔改工具前提下實現的,這樣的開發強度對市面上浩若煙海的游戲不斷重復進行是完全不可行的,而且,按照 PCGamingwiki 提供的資料,在已知的 7500 個游戲里,僅有 28 個是提供了已轉換的可修改格式。
而 NVIDAI 提供的 RTX Remix 工具則是一個基于 NVIDIA Omniverse 的免費魔改平臺,能夠為不同的游戲快速創建 RTX On 模組,這些模組能提供增強的材質、完全光線追蹤、NVIDIA DLSS 3 和 NVIDIA Reflex 支持,即使游戲使用的是老式的 DX8、DX9 世代渲染流水線。
RTX Remix 提供了被稱為 RTX Remix runtime 的 D3D9 runtime,這相當于把游戲的渲染接管為 RTX On 功能運行時,當這些老游戲如常向 D3D9 runtime 發送渲染指令的時候,RTX Remix runtime 會把這些指令攔截下來,將其重命名為不同的數字資產并重組到相同的場景中。
到了這一步后,RTX Remix 將資產和場景轉換為廣泛采用的通用場景描述(USD) 開放式 3D 框架,而這個框架也是構建和操作自定義 3D 管道的NVIDIA Omniverse平臺的基礎。
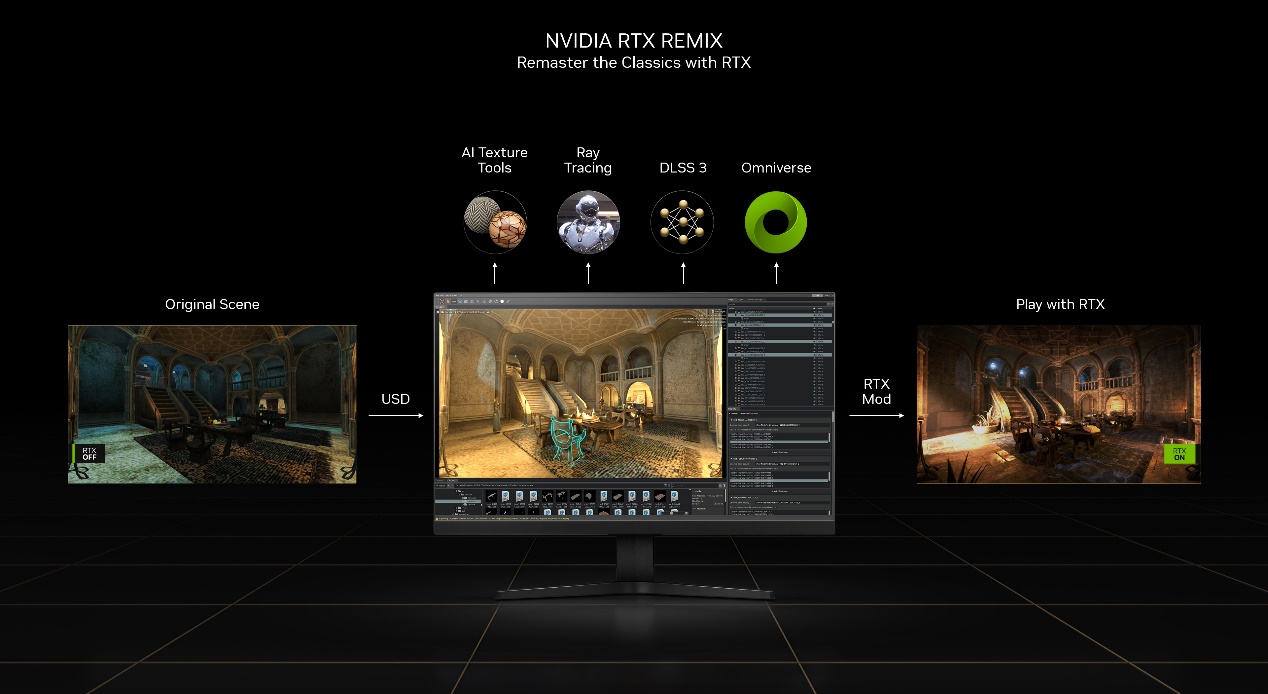
由于 RTX Remix 是基于 NVIDIA Omniverse 構建的,這些 USD 游戲資產可以輕松導入 RTX Remix 應用程序或任何其他 Omniverse 應用程序或連接器,包括游戲行業標準應用程序,例如 Adob??e Substance 3D Painter、Autodesk Maya、3ds Max、 Blender、SideFX Houdini 和 Epic Games 的虛幻引擎。
當資產從 Omniverse 連接器同步到 Remix 的視口時,魔改團隊可以協作改進和替換資產,并可視化每個更改。這個工作流程能夠改變魔改社區處理他們其游戲魔改的方式,為模組制作者提供一個統一的工作流程,將他們的知識運用到各種游戲而無需學習大量專有工具。

上圖是上古卷3晨風的游戲原圖。

上圖是上古卷軸3晨風經過 RTX Remix 魔改創作后的實際畫面
當開發人員制作好 RTX Remix 魔改包后,就可以輕松地將模組導出分享給其他玩家,玩家下載了魔改包后,扔到游戲目錄內啟動游戲,RTX Remix runtime 就可以完成剩下的工作——RTX Remix 的 64 位 Vulkan 渲染器替換掉舊的渲染 API 和系統。RTX Remix 還提供了這個 runtime 的編輯器,能夠讓玩家實時定制各種特效選項,例如修改材質屬性、添加體積霧等等。
可以看到,RTX Remix 是一個具有劃時代意義的魔改工具,對于許多舊游戲來說可能會因此再度煥發新生,在尤其是游戲開發成本越來越高的當下,為各種重制版打開了一條新的快捷開發途徑。
選擇——有必要采用光線追蹤嗎?
這是一個常見的有趣問題,特別是目前光柵化渲染還是主流的情況下。
首先,光柵渲染和光線追蹤都是用于確定可視性的一種方式。
眾所周知,光柵化渲染的原理是將場景中的每個三角形拿出來,扔到屏幕空間上,讓光柵器查找該三角形在屏幕上對應的像素,然后根據法線、深度緩存、光照、紋理等信息渲染該三角形對應的像素,理論上每個三角形都要進行這樣的操作,為了節省渲染資源,人們引入了各種剔除、修剪和隱面消除等技術,減少渲染的三角形。
而光線追蹤則是對渲染分辨率的每個像素發射一條或者一束射線,讓其擊中最接近的三角形,根據擊中點的屬性,確定是被吸收、折射還是反射(后兩種會產生衍生射線),從而產生出倒影、發散、折射等效果,周而復始。
光線追蹤本身只是一種渲染技術的通用名詞,目前已經發展出了多種實現,例如路徑跟蹤、分布式光線追蹤、雙向光線追蹤、光子映射等等,都是針對不同應用情境下提出的各具優點和缺點的光線追蹤實現,例如雙向光線追蹤可能比較適合散焦特效,分布式光線追蹤比較適合全局光照。
從光學角度看,光線追蹤才是正確的物理實現,光柵化渲染雖然也能達到基于物理渲染的效果,但是因為缺乏屏外空間信息,可能需要更多的代碼和數據才能接近,否則容易產生各種古怪的現象。
《獵天使魔女》中基于光柵化的屏幕空間倒影,出現了口紅戳眼睛的現象。
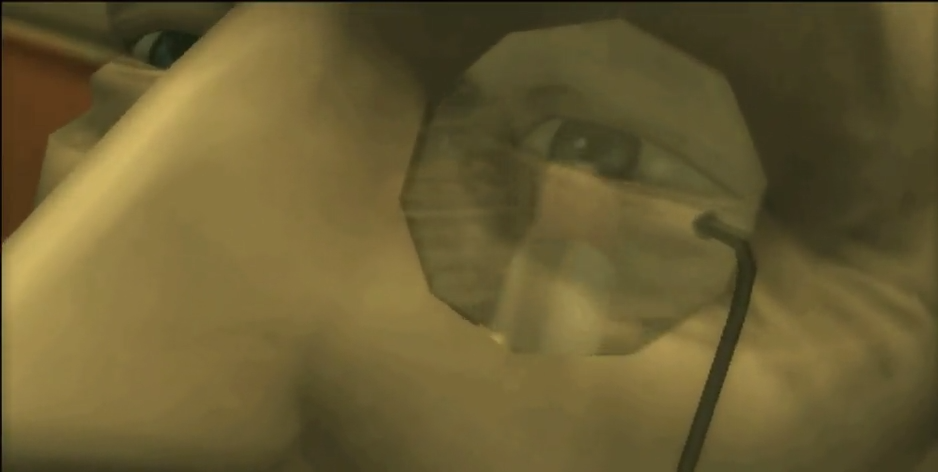
《迷失》中基于光柵化的屏幕空間倒影,貓咪在鏡子的古怪倒影。

在地鐵離去中,屏幕空間倒影(SSR)和光線追蹤倒影(RTR)的對比(SSR 里船的倒影隨著角度的變化而忽隱忽現,而光線追蹤倒影則保持很好的一貫性):

即使是某些宣稱是光線追蹤的情況,但是由于和真正的光線追蹤實現完全不是一回事而存在各種問題,例如Reshade 特效外掛基于屏幕空間實現的偽光線追蹤全局光照容易產生忽有忽無的現象(黃色色染隨著梯子移出屏幕外后就突然消失了):

既然光線追蹤或者說真正的光線追蹤能產生更逼真的畫面,那么為何在 RTX GPU 之前極少看到呢?
答案相信大家都聽說過,那就是光線追蹤需要大量的計算。
光線追蹤產生衍生射線后,會繼續反彈射向下一個物體,且反彈的方向可能是隨機的,單條射線難以準確計算出整個物體表面的明暗,隨之就會產生噪點,為了減少噪點,要嘛就是每個像素發射更多的射線,例如數千條射線,又或者是結合隨機算法進行累積,這些辦法都會導致計算量幾何級上升,而更復雜的場景和模型(例如復雜的透明模型)會讓計算量在此基礎上再跳若干個幾何級。
NVIDIA 在 Volta 世代開始引入的光線追蹤就是支持使用張量內核進行降噪處理,可以實現較少的射線實現接近參考目標圖的效果。
到了 Turning 世代,NVIDIA 引入了 RTCore 來實現光線追蹤求交加速,目前所有的 GPU 硬件光線追蹤加速基本上都是類似于 Turing——通過加入求交加速模塊來加速光線追蹤,所不同的主要是具體的規模和涵蓋的加速特性范圍(例如 NVIDIA RTCore 和 Intel RTU 還支持遍歷、排序,AMD RDNA2 則還有欠缺,RDNA 3 有少量改進)。

上圖是分別是參考圖、采用 NVIDIA 實時降噪器處理的效果以及輸入降噪器的光線追蹤渲染畫面
目前絕大多數的硬件光線追蹤加速游戲都是采用了混合渲染流水線,也就是先用光柵化確定可視性,然后使用光線追蹤對屏幕區域中特定的位置進行光線追蹤計算,這不失為一種畫質與性能的折衷,例如 AMD 的 SSSR 就是針對場景中不同位置使用傳統光柵 SSR 和DXR 光線追蹤的倒影算法。
經過 4 年的發展,光線追蹤加速已經不再陌生,除了折射、倒影、陰影等特效處理外,還有一個重要的應用現在開始逐漸增多,那就是全局光照(Global Illumination,簡稱 GI)的普遍實現。
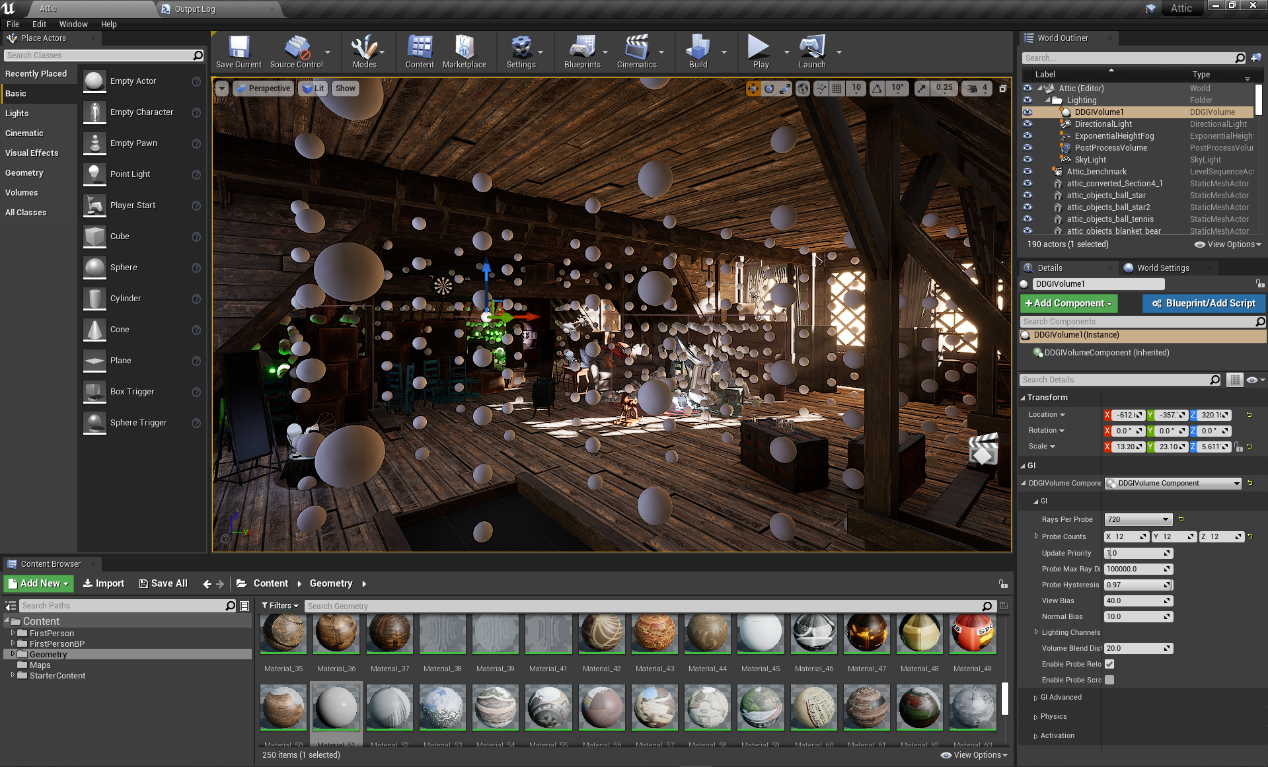
上圖是虛幻引擎編輯器里展示啟用 RTXGI,圖中的圓球就是全局光照特效常見的探針示意。

上圖是游戲 ICARUS 啟用基于 RTXGI 全局光照后效果
NVIDIA 在這方面有較長的積累,例如在 2019 年提出的 DDGI(現在的營銷名稱為 RTXGI),可以在無噪點的情況下實現實時全動態光線追蹤全局光照。AMD 在今年(2022 年)10 月也發布了一篇論文,提出了名為 GI 1.0 的全局光照實現辦法,在這篇論文中,雖然 AMD RX 6900XT 光線追蹤部分的性能只有 RTX 3080 的一半,但是憑借高速緩存的優勢,最終達到了持平的性能。
另一個挑戰則是場景光照的豐富性問題,例如目前的光線追蹤游戲一般只有兩個到十六個主光源,即使是 Quake 2 RTX 中也不過是 100 多個用于光線追蹤的光源,NVIDIA 為此提出了 RTXDI 技術(在 2021 年正式采用這個名稱,主要基于 NVIDIA 2020 年前提出的 ReSTIR 技術)。


RTXDI 嘗試近似經典渲染方程的方式進行計算,經過優化后,每個像素只用兩條射線采樣,結合 NRD 專門為 RTXDI 優化的 RELAX 降噪器,透過多種重采樣技術,就能對百萬級數量的光源實施光線追蹤,徹底摒棄其他所有陰影技術以及環境遮蔽技術,并且可以和 RTXGI 結合實現更逼真絢麗的渲染效果。
RTXDI 可以在 NVIDIA、AMD 等支持 DXR 和 Vulkan 光線追蹤擴展的 GPU 上運行,不僅游戲中可以使用,還有一些開發人員已經提供了支持 Blender 的 RTXDI 渲染引擎,適用性相當廣。
說了這么多作為鋪墊,接下來我要做一些光線追蹤的相關測試了,這部分分為主要是偏底層的測試和實際游戲測試,手頭有一片 GeForce RTX 3080 Ti FE 和七彩虹的 iGame GeForce RTX 4080 16GB Ultra W OC,相對于之前的公版測試,我這次主要是要一些延伸性的測試,特別是我的 AMD Ryzen 7 5800X 平臺上,啟用光線追蹤是否下相當于“免費”。
測試平臺
CPU:AMD Ryzen 7 5800X 鎖定 4.5GHz,開啟超線程
主板:華碩 ROG Strix X570E Gaming
內存:TT Tough DDR4-3600 8GB*4
電源:TT Tough 850W 80 Plus 白金認證
顯卡:七彩虹iGame GeForce RTX 4080 16GB Ultra W OC
顯卡:NVIDIA GeForce RTX 3080 Ti FE
顯示器:DELL U2413
驅動程序:GeForce Game Ready 驅動 v526.98
操作系統:Windows 11 22H2 22621.819 專業工作站版,電源管理卓越性能模式,關閉 Windows Defender
主板 BIOS 設定:開啟 ResizableBAR 支持
七彩虹 iGame GeForce RTX 4080 Ultra W OC
這次參與對比的新卡是來自七彩虹的 iGame 系列 GeForce RTX 4080 16GB Ultra W OC:




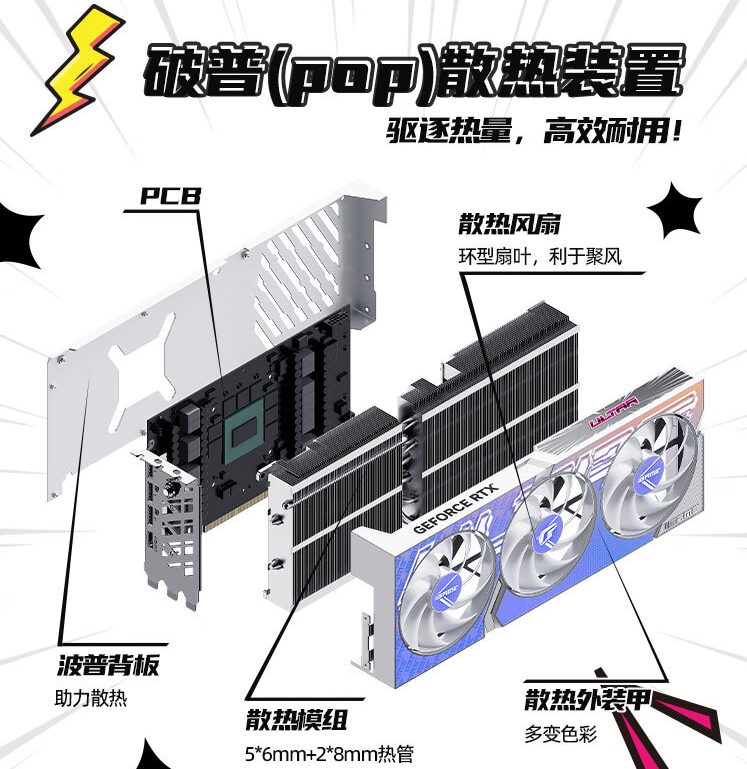
七彩虹的 iGame GeForce RTX 4080 16GB Ultra W OC 是我接觸的第一款非公版 RTX 4080,和公版一體化設計相比,iGame GeForce RTX 4080 16GB Ultra W OC 的更長,這樣設計的目的是為了容納 3 個風扇,提供更良好的散熱效果。
散熱器外甲采用波普藝術風格,顯卡側面引人矚目的是“漫畫特效”的Ultra燈組(可以使用 iGame Center 2.0 進行燈光同步設置),在開機后會亮起,內部散熱模組采用了 5*6 mm + 2*8 mm 熱管,熱管和鰭片采用了回流焊高度融為一體,三組雙滾珠軸承風扇的扇葉直徑均達到 100mm,9 片風扇葉片是利于聚風的環形葉片。
位于頂部的電源接口是12VHPWR(PCIE 5.0)電源接口,隨卡提供了一條 3* 8pin PEG 轉接線,當然如果可以的話最好電源也采用 ATX 3.0 帶 12VHPWR 連接線,這樣可以讓機箱空間更簡潔。
雖然七彩虹iGame GeForce RTX 4080 16GB Ultra W OC 的尺寸比 NVIDIA FE 公版更長(大約是 32.5cm vs 30cm),但是在整體重量上由于采用了三風扇開放式散熱設計反而要輕不少,不像公版那樣有一大圈金屬包圍,這樣的好處除了散熱更好外,對于主板來說也是降低了負擔,而用戶需要注意的是機箱內部需要有足夠的空間。
七彩虹iGame GeForce RTX 4080 16GB Ultra W OC 提供了一鍵超頻功能,在顯卡擋板處有一個按鈕,按下后就能啟用一鍵超頻:
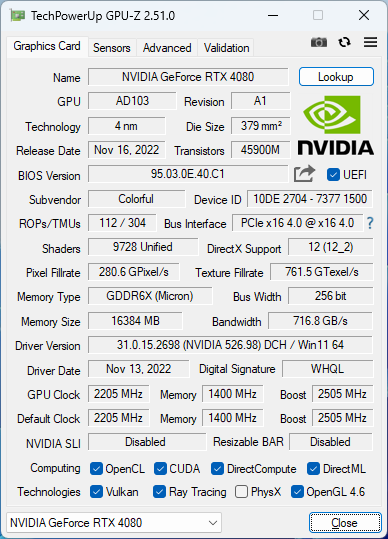
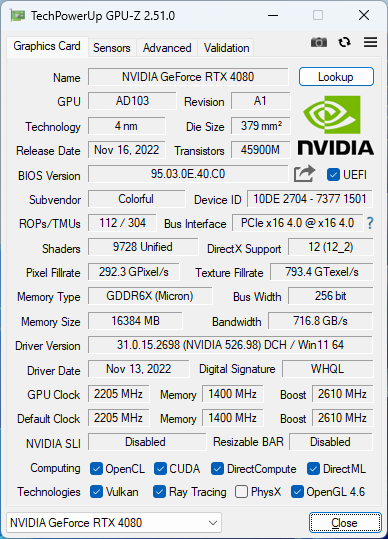
使用 3DMark Speed Way 測試結果如下:

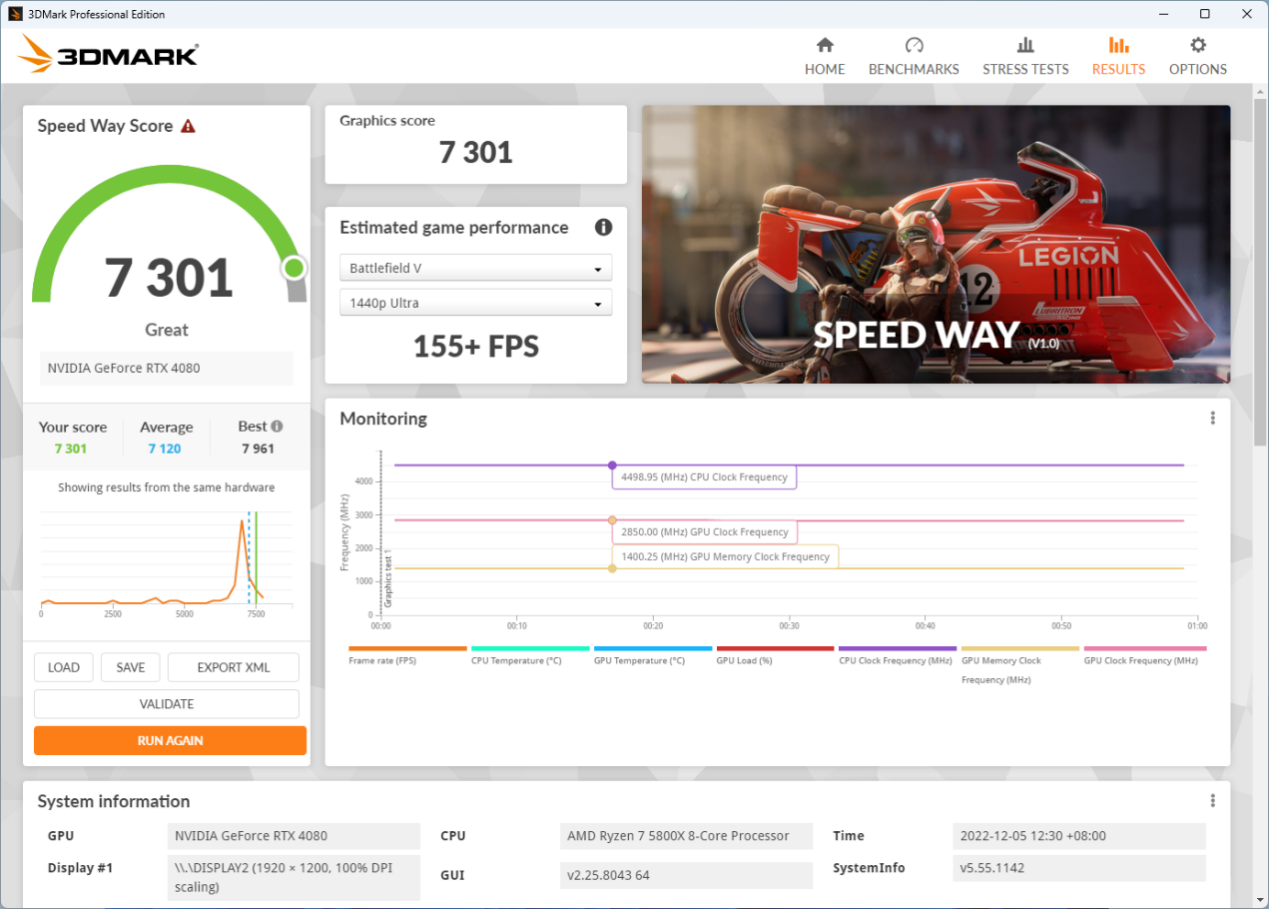
一鍵超頻略顯保守,性能改善幅度大約是 1.3%,好處是比較簡單,而且是有官方質保的。
下面就讓我們進入具體的光線追蹤測試環節。
底層測試
底層測試的目的是希望盡可能獲知硬件的理論性能,特別是像 RTCore 相對較少資料的單元,我們對其細節更是充滿好奇。
底層測試——光線追蹤峰值性能測試
為了探測 GeForce RTX 4080 的光線追蹤底層性能,我這次使用 Matt Pettineo 的 DXR Patht Tracer 進行了簡單的對比,測試條件是每像素 16 射線、8 次反彈、32 光源,并且啟用了若干常見的渲染效果:

這是一個很簡單的場景,但是請注意,我們測試的是一個路徑跟蹤器,性能和取樣數、光照路徑長度有較大關系。
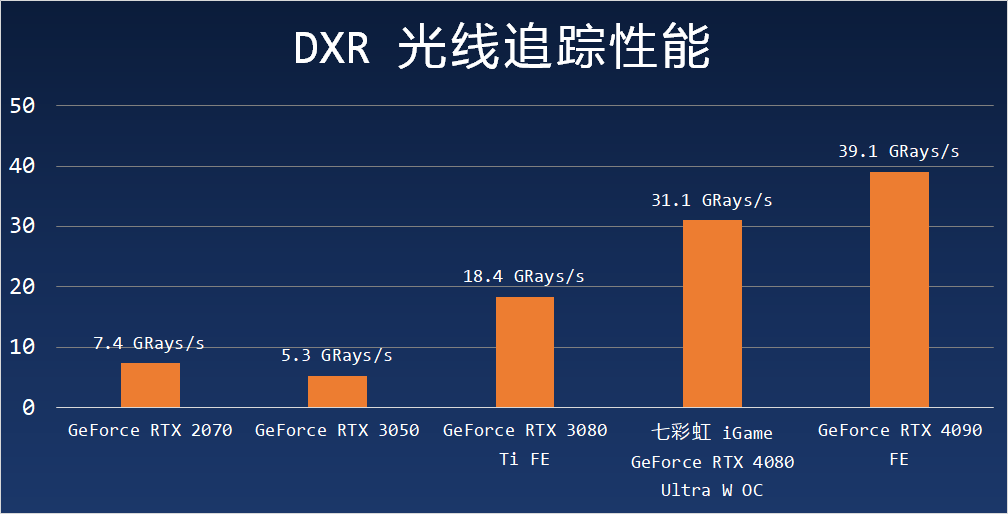
前面我們說過,常見的光線追蹤渲染實現方式是指從攝像機方向發射射線穿過屏幕像素直到擊中場景中某個三角形,這一步被稱作求交,在完成求交計算后,光線渲染程序中的 anyhit 代碼會根據擊中點的屬性確定是否產生衍生射線以及選擇相應的后續計算。
由于會產生多次的衍生射線碰撞,光線追蹤需要進行大量簡單而重復的求交測試計算,所以求交測試模塊是光線追蹤加速單元的最主要組成部分,我們在這里的底層測試就是為了探測出 GPU進行一定特效處理的情況下每秒可以進行的射線求交能力。
從測試結果來看,RTX 4080 可以每秒跑出 31.1 Grays(Giga Rays,十億條射線),而 RTX 3080 Ti 則是 18.4 Grays,兩者此時的性能比值為 1.69 倍。
底層測試——Ray Tracing in Vulkan
這里我使用的是 GPSnoopy 的 Ray Tracing in Vulkan,這是 Tanguy Fautre 按照 Peter Shirley 的 Ray Tracing in One Weekend光線追蹤短訓教程在 github 上發布的代碼實現,最初使用的是 NVIDIA 私有 Vulkan 擴展,后來 KHR 發布了官方 Vulkan 光線追蹤擴展后,所有代碼也隨之移植到官方 Vulkan 擴展上來,這意味著包括 AMD、Intel 等 GPU 也能運行這個程序。
如果有看過我之前測試的話,應該也了解到我之前是跑過這個程序的。這次我測試的是 github 上的最新代碼版本,使用 VS 2022 和 Vulkan SDK 編譯。
程序提供了 5 個場景,分別是:
- Ray Tracing In One Weekend
- Planets In One Weekend
- Lucy In One Weekend
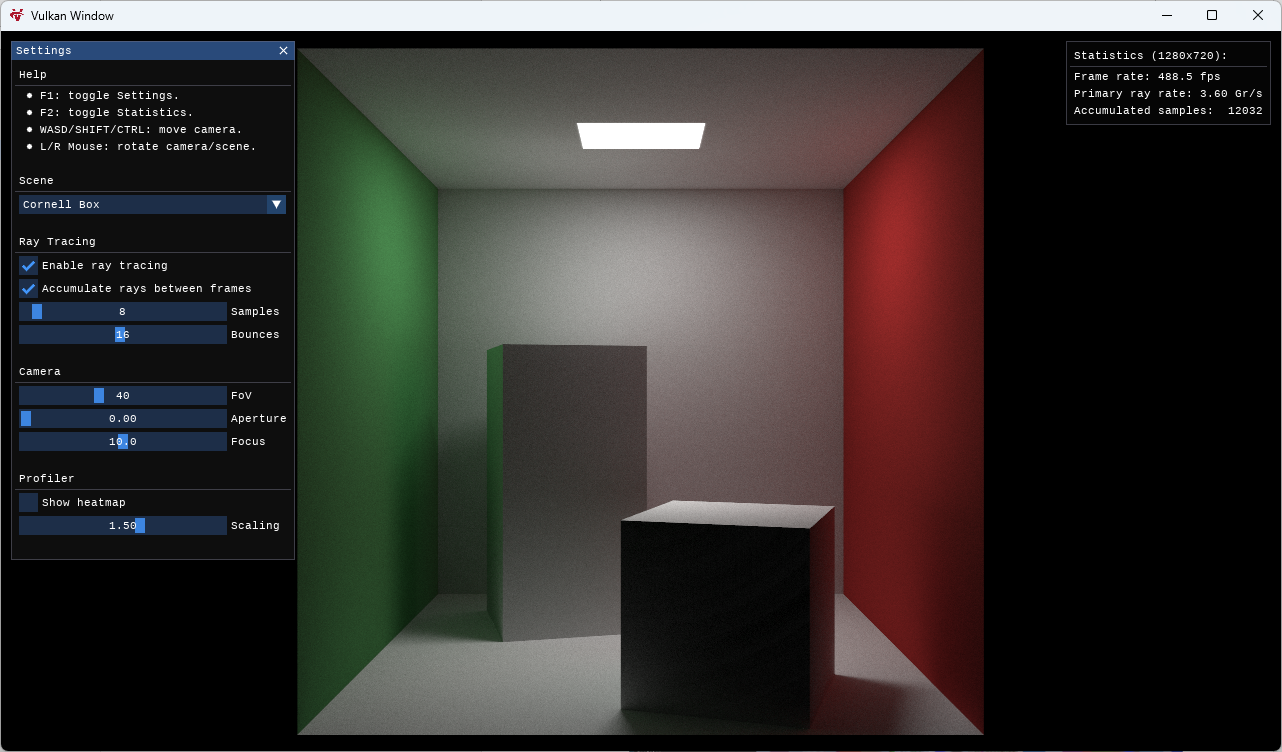
- Cornell Box
- Cornell Box & Lucy
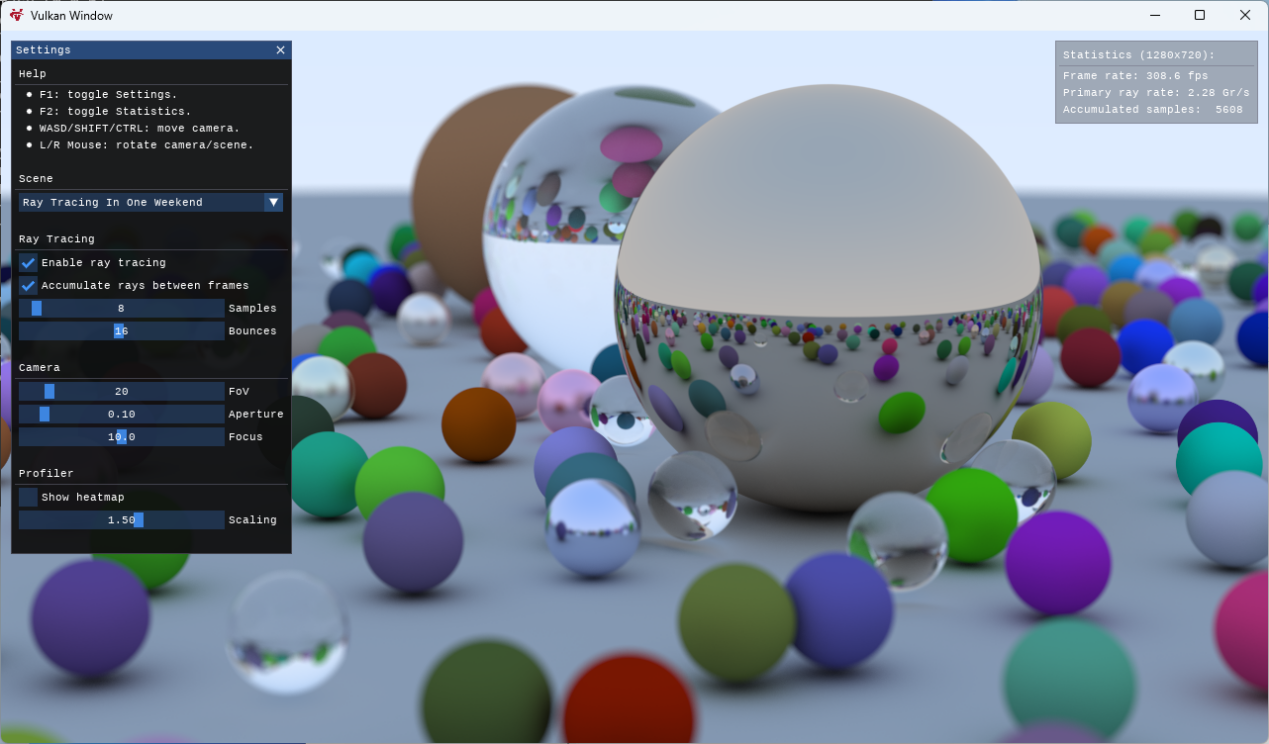

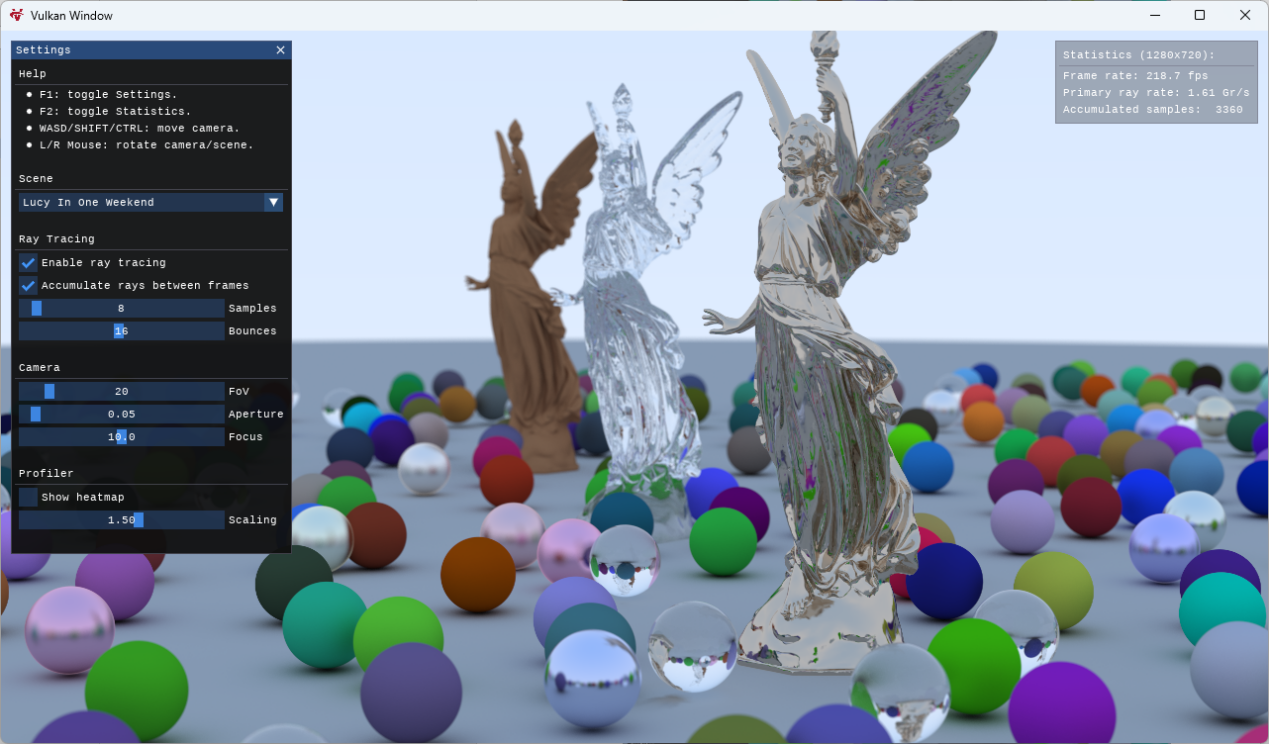
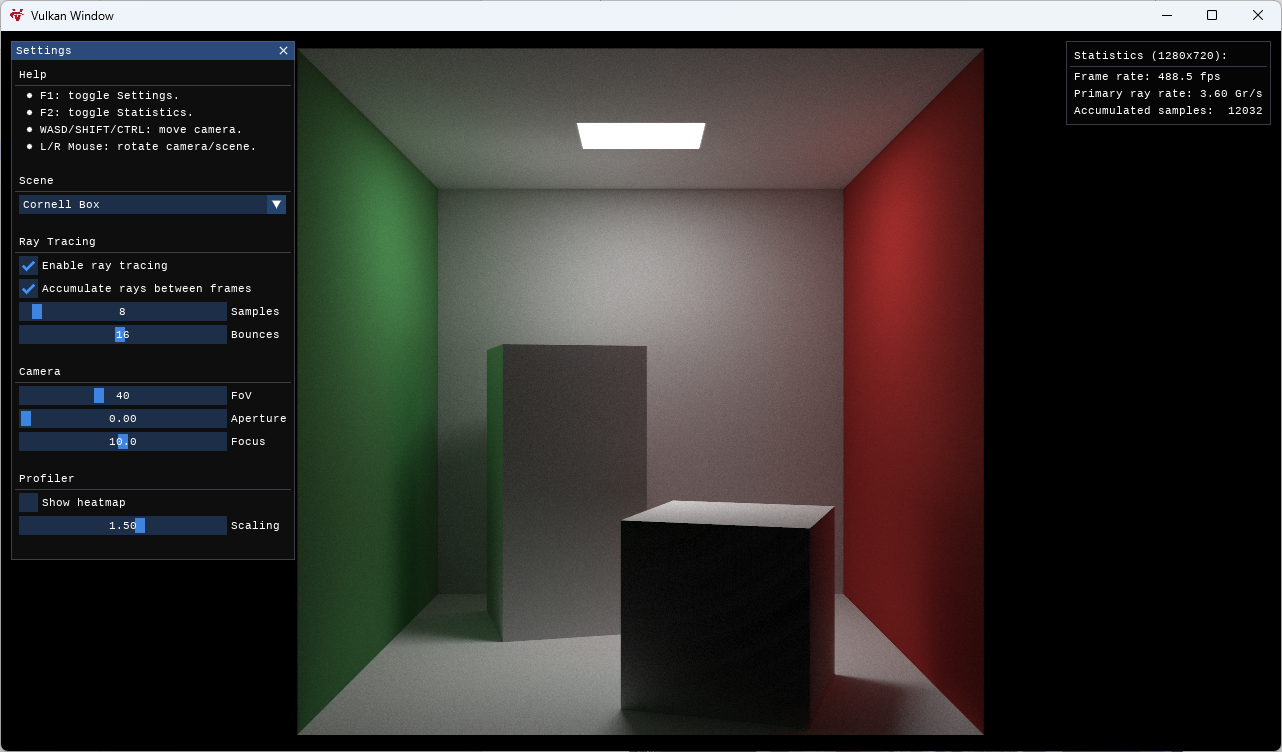
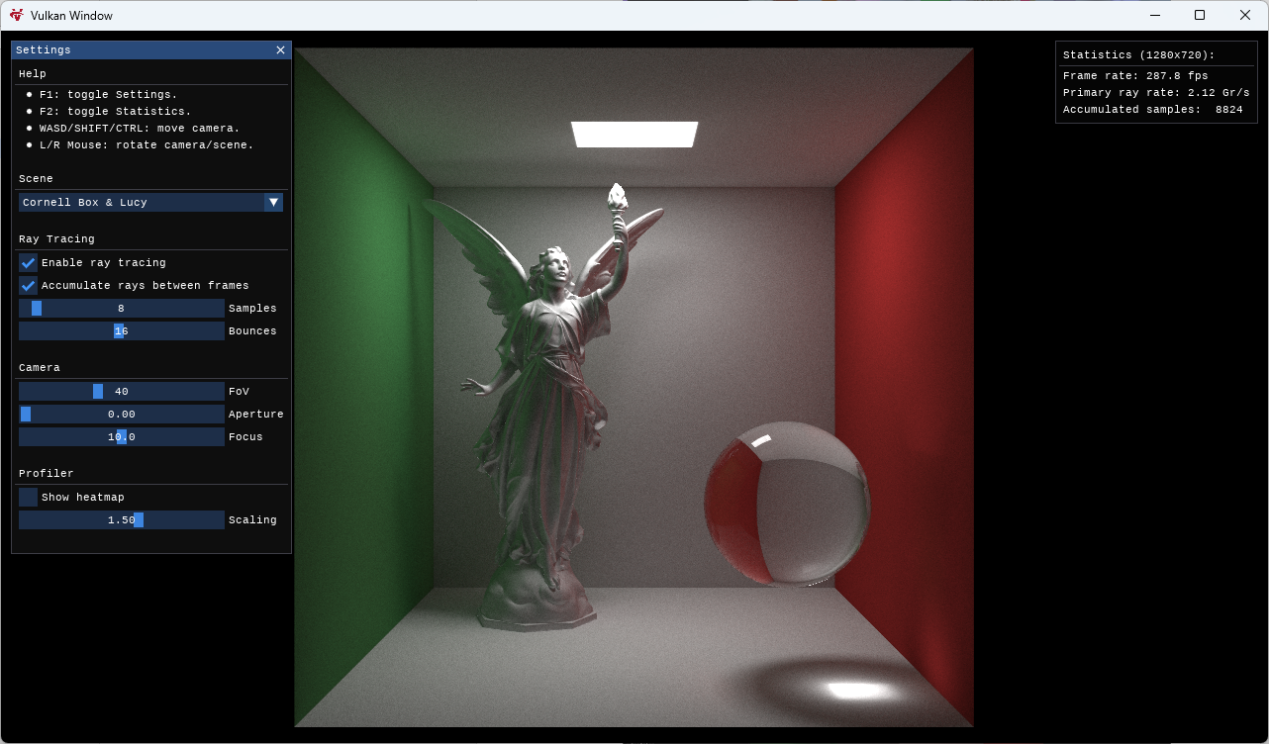
程序允許修改射線取樣數量(默認每像素 8 條射線,最高 128 條)和射線反彈次數(默認 16 次,最高 32 次)。
雖然程序每個場景跑一遍只需要 60 秒,但是我這次使用的測試腳本是涵蓋了每像素 1、2、4、8、16、32 條射線以及一次、兩次、四次、八次、十六次、三十二次反彈,一輪跑下來大概需要數個小時。
測試結果如下:
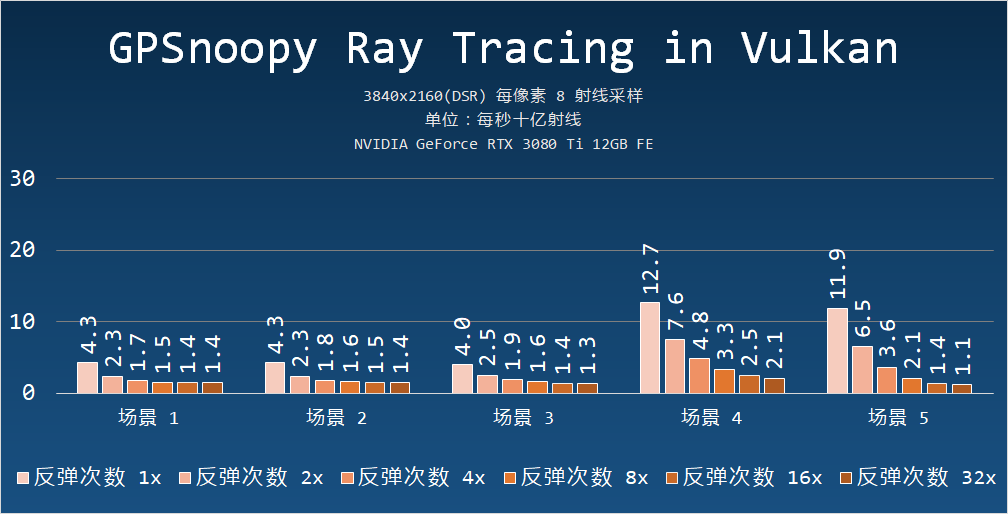
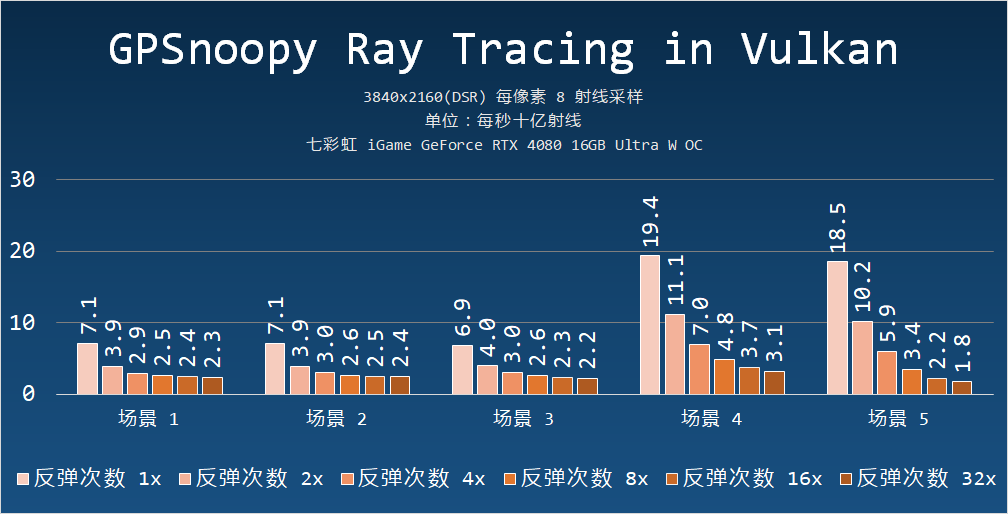
由于程序渲染的場景相對簡單,也不涉及降噪等著色器操作,比較容易體現光線追蹤加速環節或者說求交性能上的性能差別。
由于 RTCore 對我們來說還是一個黑匣子,里面好多細節我們都知之甚少,NVIDIA 提供了一個名為 RT TFLOPS 的指標,但是這個東西是根據游戲運算量統計百分比,揉合了 SM 單精度性能、RTCore 等效性能、張量內核性能的東東,純粹度略顯不夠。
為了簡化描述,我這里將每個 RTCore 每周期跑的操作集稱之為 RTCore-Ops。
七彩虹iGame GeForce RTX 4080 16GB 運行程序時候的 3D 內核頻率為 2805 MHz,乘與 76 個第三代 RTCore 的話,理論上就是每秒跑 213,180 百萬次第三代 RTCore-OPs。
NVIDIA GeForce RTX 3080 Ti 12GB 運行程序時的頻率波動相對較大,在 1835 MHz 到 1905 MHz 之間,取中間值 1870MHz 的話,乘與 80 個第二代 RTCore,那就是每秒跑 149,600 百萬次第二代 RTCore-Ops。
單純看 RTCore-Ops 的話,七彩虹iGame GeForce RTX 4080 16GB 是 NVIDIA GeForce RTX 3080 Ti 12GB 的 1.42 倍。
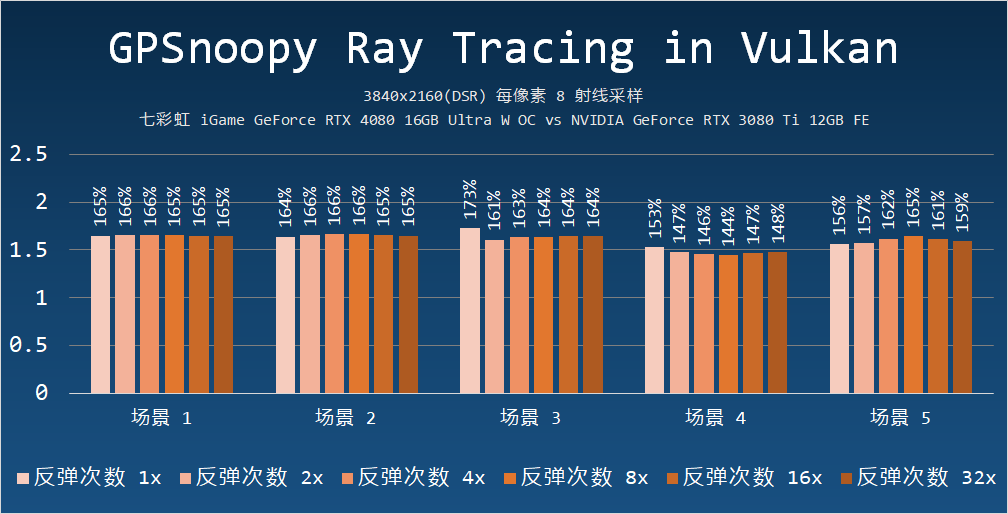
但是從 GPSnoopy Ray Tracing in Vulkan 的測試結果來看,七彩虹iGame GeForce RTX 4080 16GB 的實測光線追蹤性能是 NVIDIA GeForce RTX 3080 Ti 12GB 的 1.61 倍(平均值),多出來的 20% 顯然是來自于第三代 RTCore 或更大高速緩存(64MB L2 vs 6MB L2)所帶來的。
我還測試了包括其他每周期射線數量(每像素 1、2、4、16、32 射線)的情況,在較少采樣的情況下,例如每像素一射線的時候,兩者的平均性能比值差別會少些——152%,在更多采樣的時候,性能比值基本一樣。
提升幅度較少的是場景 4,這個場景的特點是沒有透明、鏡面物體,這意味著衍生射線的數量以及隨之而來的復雜著色計算會更少,在每像素 1 條射線的時候,七彩虹iGame GeForce RTX 4080 16GB 是 RTX 3080 Ti 的 142%,相當于兩者的 RTCore-Ops 比值。
在采樣數量增加到每像素 8 條射線后,七彩虹iGame GeForce RTX 4080 16GB 在場景四的性能是 NVIDIA GeForce RTX 3080 Ti 12GB 的 148%,依然接近兩者 RTCore-Ops 1.42 倍比值。
由于支持提供 RTCore 狀態特性信息 Nsight 目前只對企業用戶以 NDA 的形式提供,普通人難以接觸,故此想進一步準確獲知相關細節的正門目前是堵死的,因此這次測試只能根據表面結果做判斷。
考慮到測試場景不涉及動態模糊或者其他射線插值計算的情況,因此第三代 RTCore 的每周期三角形求交能力兩倍于第二代 RTCore 的特性在這里應該是體現不出來的。
對于上面這些測試結果,我很容易得出下面的結論:
對于涉及較多透明、鏡面反射物體的場景,NVIDIA GeForce RTX 3080 Ti 12GB 或者說 Ada 架構可以從較大的高速緩存以及著色器性能顯著獲益,而對于透明、鏡面或者說反彈次數較少的場景,基本上就是兩者單元規模和頻率乘積的高低區別。
游戲實測
在游戲測試方面,我這次打算精簡一下,只選擇三款光線追蹤游戲,分別是賽博朋克 2077、地鐵逃離增強版以及蜘蛛俠重制版,其中賽博朋客 2077 具備光線追蹤倒影、陰影計算,地鐵離去增強版采用了光線追蹤來實現全局光照、倒影、陰影,蜘蛛俠重制版是從主機平臺移植過來的,提供了光線追蹤倒影特效,上述上個游戲均提供了 DLSS 超分辨率技術,其中蜘蛛俠重制版以正式版的方式提供了 DLSS 3 插幀支持,賽博朋克 2077 以內測版的方式提供了 DLSS 3 插幀支持,地鐵逃離增強版提供了 DLSS 2 支持。
地鐵逃離增強版
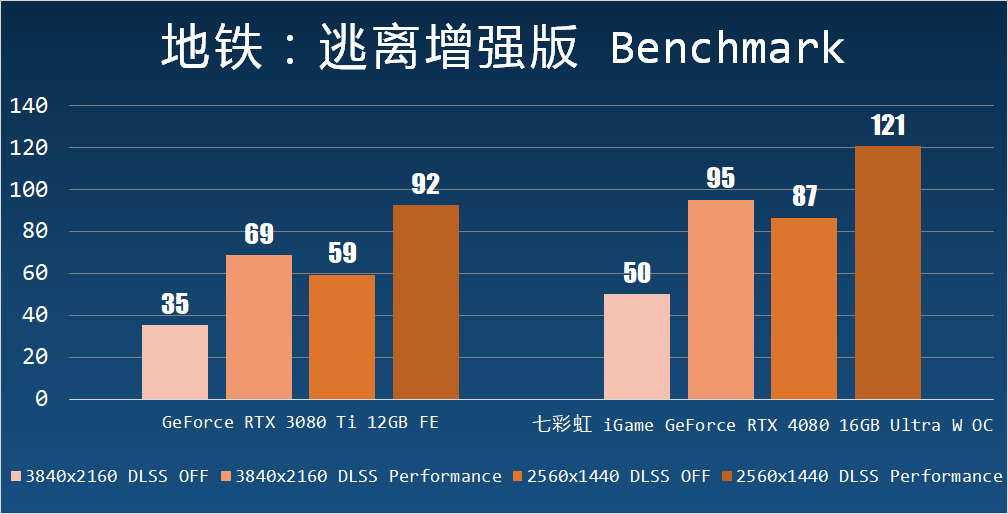
地鐵:逃離增強版:地鐵逃離增強版是一個出色的第一人稱單人游戲,采用 4A Engine 開發,是第一個強制要求顯卡必須支持 DXR 的游戲。
七彩虹 iGame GeForce RTX 4080 16GB Ultra W OC 在這個游戲中實現了 95fps 的 4K 全開最高 DLSS Performance 性能,在 2560×1440 則是達到了 121 fps。
蜘蛛俠重制版
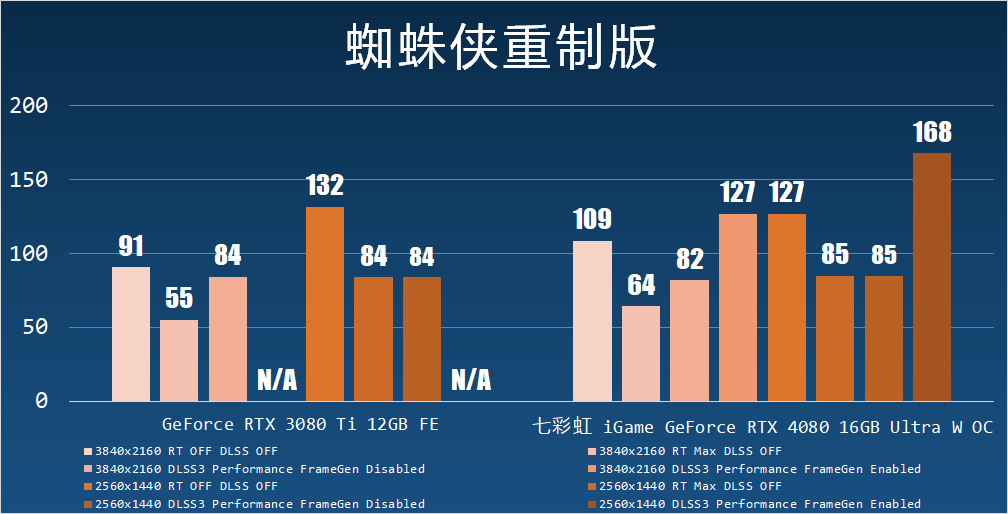
蜘蛛俠重制版:蜘蛛俠重制版是一個移植自游戲機的第三人稱動作游戲,采用 Insomniac 游戲引擎,最新版提供了 DLSS 3 插幀支持。
從測試結果來看,蜘蛛俠重制版在我們的測試平臺上遇到了 CPU 性能瓶頸,在 2560×1440 的時候啟用光線追蹤+DLSS 3 插幀可以達到 1.73 倍于插幀之前的性能。相較之下,4K 光線追蹤+ DLSS 3 插幀是啟用插幀之前的 1.48 倍。
和關閉光線追蹤相比,啟用光線追蹤 + DLSS 2 后的性能會更快,以七彩虹 iGame GeForce RTX 4080 16GB Ultra W OC 為例,此時的性能是關閉光線追蹤時的 1.24 倍。
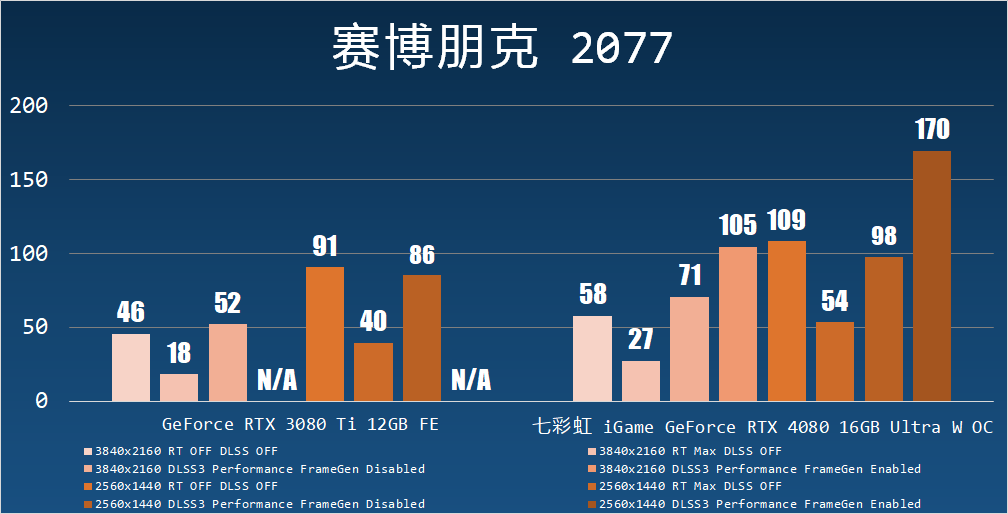
賽博朋克 2077
賽博朋克 2077:賽博朋克 2077 是一個跨平臺游戲,采用的游戲引擎是 REDengine 4,提供了光線追蹤倒影、光線追蹤陰影等特效支持,我們這里測試的版本是提供了 DLSS 3 插幀支持內測版。
NVIDIA 在 9 月份的時候 已經將賽博朋克 2077 列為 DLSS 3 游戲,但是具體的正式支持時間尚不清楚,可能會和 Overdrive 光線追蹤(RTXDI)一同發布?
在 4K 分辨率下,七彩虹 iGame GeForce RTX 4080 16GB Ultra W OC 啟用光線追蹤+ DLSS 2 后的性能是關閉光線追蹤、不啟用 DLSS 2 的 1.22 倍。在打開光線追蹤模式下, DLSS 2 Performance 能實現 2.62 倍于啟用 DLSS 2 之前的性能。
對于 DLSS 3 插幀性能表現,作為參考,七彩虹 iGame GeForce RTX 4080 16GB Ultra W OC 啟用 DLSS 3 插幀后,4K 時的性能提升了 47%(如果是單純和啟用光線追蹤相比則是 289%),而在遭遇 CPU 性能瓶頸的 2560×1440 下提升幅度達到了 73%(如果是單純和啟用光線追蹤相比則是 215%)。
為了獲知更多的細節,我將蜘蛛俠重制版和賽博朋克 2077 的更多 CaoFrameX 細化測試結果整理為下面的兩個表格:
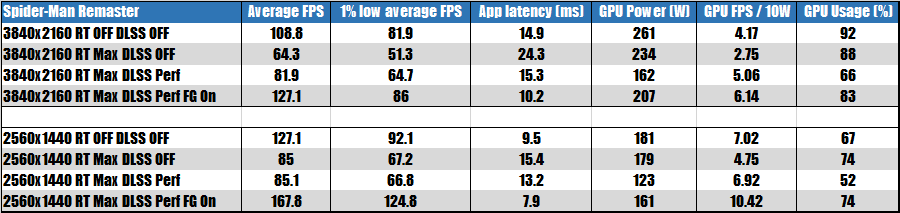
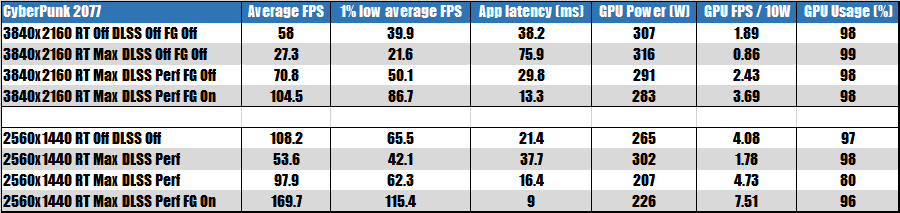
上面表格中除了大家常見的平均幀率外,還有低于 1% 的平均幀率、應用時延、GPU 耗電、GPU 每 10 瓦耗電幀率以及 GPU 占用率等指標。
1% 頻率低幀率是指按照從最高到最低幀率來排列,然后取位于末尾或者說最慢的 1% 幀率進行平均取得的均值,英文一般稱為 1% Low Averags FPS被認為是反映卡頓的最佳指標,這個指標越高游戲流暢性感受就越好。如果你對游戲卡頓比較敏感的話,建議關注一下這個指標。
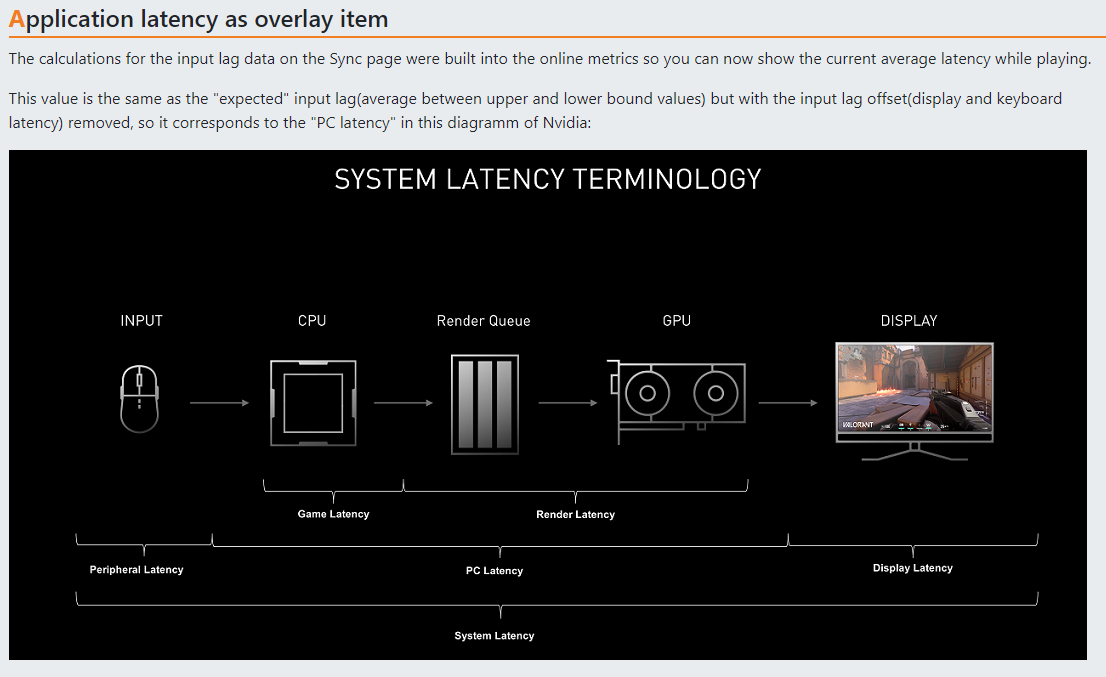
關于 App Latency 指標,按照作者的介紹(以及presentmon1、presentmon2)的信息, App Latency類似于 NVIDIA Frameview 中的 PCLatency,是指電腦 I/O 端口接收到外部人機設備指令后到顯卡完成渲染發送數據到顯示器的這段耗時。這個指標完全獨立于顯示器和人機設備,只考慮電腦系統內的情況,可以最大限度反映電腦內部渲染時延問題,該指標的單位一般是毫秒表示。
但是根據我的實際對比,發現 App Latency 和 PCLatency 還是存在一定差異的,特別是在啟用了 DLSS 后:
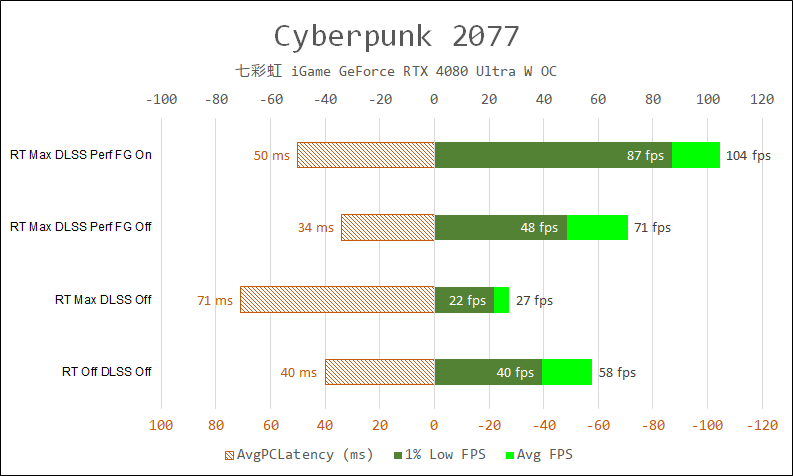
可以看出,在 DLSS Perf + FG on 的時候,PCLatency 測試結果為 50ms,比 CapFrameX 的 13ms 高不少。
在啟用光線追蹤后,單純啟用 DLSS 的話,PCL 只有 34ms,比關閉光線追蹤、關閉 DLSS 的時候快 29.4%,改善幅度比平均幀率還高。
GPU Power 表示顯卡的全卡耗電,而 GPU fps/10W 代表的是每 10 瓦耗電能達成的幀率。
GPU Usage 表示測試過程的平均 GPU 占用率。
從測試結果可以確認蜘蛛俠重制版在 2560×1440 的時候的確更容易受到 CPU 性能影響,在啟用 DLSS 2 后 GPU 平均占用率只有 52%,此時耗電為 123 瓦,每 10 瓦幀率為 6.92 fps/10瓦。
啟用 DLSS 3 插幀后,耗電會有所提升,達到 161 瓦,增加 30%,但是性能耗電比會顯著提升達到 10.42 fps/10瓦,提升了 51%。
網絡上有人表示關閉超線程的話,蜘蛛俠重制版的性能會有所提升,我試了一下,的確是一定的改善:

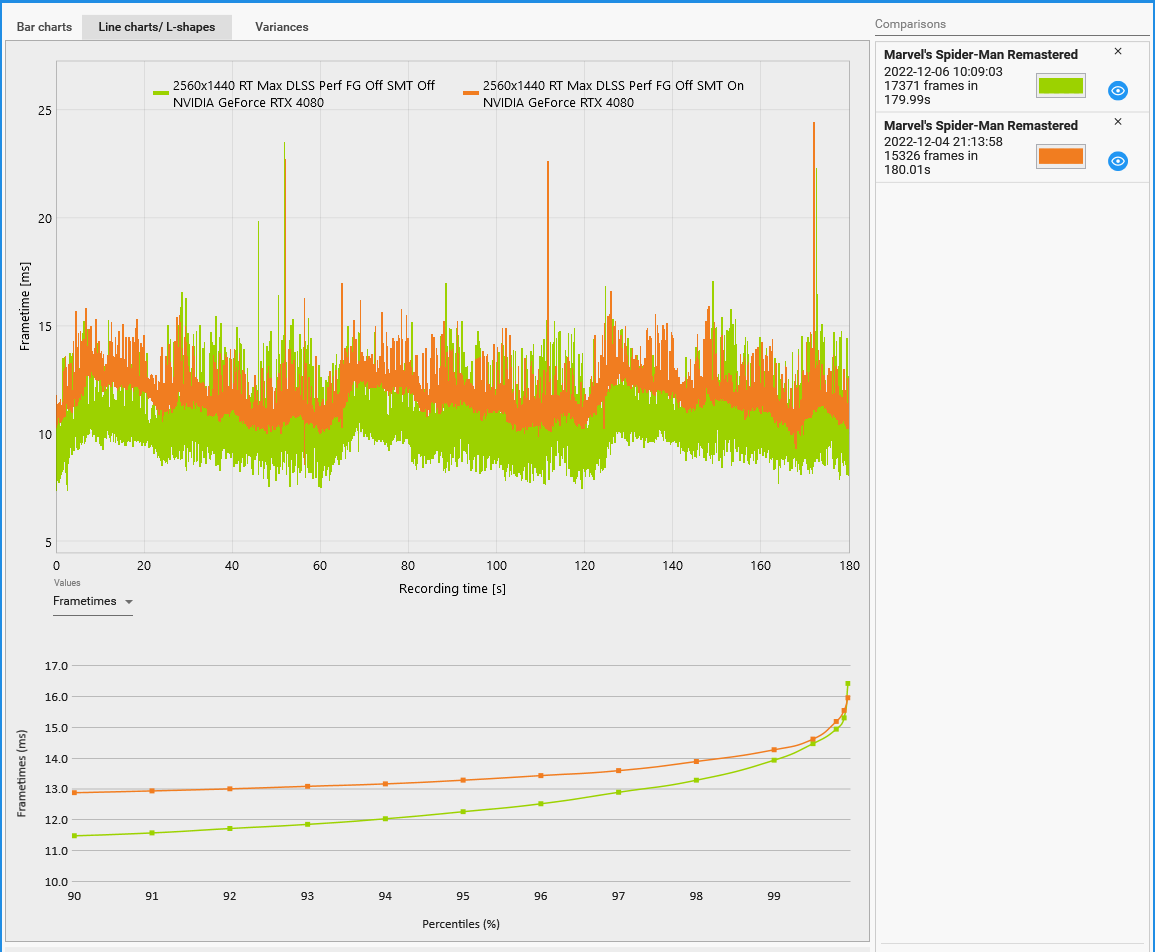
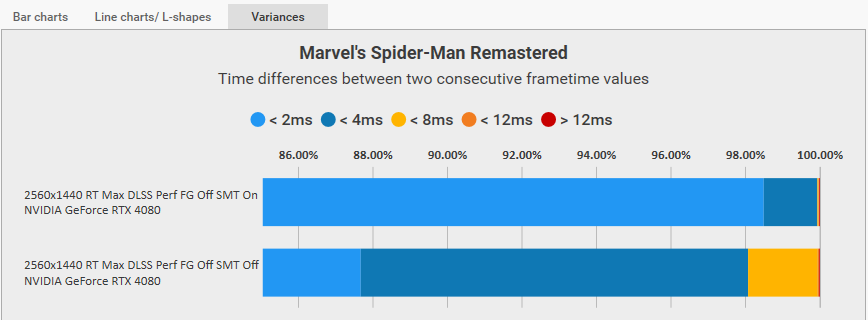
幀率從 85.1 fps 提升到了 96.5fps,不過 1% Low Avg 只有 1 fps 的改善,最慢幀時間有較大改善。
根據記錄數據,此時 CPU 的耗電是 86 瓦,降低了兩瓦,而 CPU 最大使用率從 81% 提升到了 96%,GPU 耗電基本持平——125 瓦。
如果你是游戲玩家的話,不妨嘗試到 BIOS 里關閉掉超線程,很可能會有一點小驚喜。
全文總結
經過四年的發展,光線追蹤在軟硬件方面已經有了大幅度的改善,當前的旗艦硬件光線追蹤 GPU 在 4K 分辨率下配合超分辨率、插幀等技術下輕松每秒破百幀,在這樣硬件能力下,越來越多游戲和應用開發商紛紛加入到支持硬件光線追蹤加速的行列,像 PC 平臺上的硬件光線追蹤游戲數量就從零增加到 100 款以上。
光線追蹤對畫面的改善不是體現在紋理、模型的細節上,而是更真實的物理光學體驗,例如自然而然的全局光照(RTXGI)、不會忽有忽無的倒影、“接地氣”的陰影、繽紛絢麗的夜景(RTXDI)等等。


硬件光柵渲染經過近 30 年的發展,能做的改善已經不多,難以克服的地方是時候交給光線追蹤來完成了。
在這次測試中,我們了解了 GeForce RTX 4080 16GB 的峰值光線追蹤性能大約是每秒 31.1 GRays,是上一代 Ampere 架構 RTX 3080 Ti 每秒 18.4 GRays 的 1.69 倍,在演示場景測試中一般幅度會在 1.65 倍左右,而在游戲中,這個幅度是 1.35 倍左右,原因和目前游戲基本采用混合渲染流水線有關。在混合渲染流水線中,游戲使用光柵器確定每個三角形在屏幕上的位置,然后根據需求決定是否在這些位置上進行光線追蹤渲染。
DLSS 技術是實時光線追蹤的最佳伴侶,經過多次版本迭代后,DLSS 的畫質有了顯著的改善,新加入的插幀技術讓需要更高畫面流暢體驗的玩家多了選擇。
對于旗艦級的顯卡例如七彩虹 iGame GeForce RTX 4080 Ultra W OC 來說,CPU 的確會在很多游戲中成為瓶頸,但是隨著 DLSS 3 插幀技術的推廣,即使 CPU 成為瓶頸,也能實現更平滑的畫面流暢體驗,關閉超線程有時候會帶來一定的小驚喜。
當然,如果游戲本身并非電競類,你可以嘗試透過幀率約束將游戲幀率上限 60fps,這并非沒有意義,因為幀率更低的話,意味著耗電、風扇噪音更低,同樣能帶來更好的游戲體驗。
]]>